検索ロジックについて
ゆるふわ検索の検索エンジン開発元による、検索の仕組みの解説です。
ゆるふわ検索エンジンは、ベースとして 「TF-IDF」 という機械学習のしくみを使っていますが、その概念をできるだけ平易な表現でご紹介します。
TF-IDF
TF-IDF(Term Frequency – Inverse Document Frequency)とは、文書中に含まれる単語の重要度を評価する手法の1つで、ある文書を特徴づける重要な単語を抽出したい時に有効となる手法です。
- TF(Term Frequency)
- ある文書における単語の出現頻度です。いくつかの文書があり、ある文書中に出現する頻度が多ければ多いほど、その単語は重要である可能性が高いと評価するものです。
- IDF(Inverse Document Frequency)
- 「逆文書頻度」 と呼ばれていて、ある単語がいくつの文書で使われているかを表しています。いろいろな文書で頻繁に使われている単語は重要度が低いと評価され、IDF値は低くなります。逆に、特定の文書にしか登場しないレアな単語であればあるほど、IDF値は高くなります。
TF-IDFは、TFとIDFの2つの指標を掛け合わせた値になります。
簡単な計算式で表すと下記のようになります。
TF-IDF = TF(単語の出現頻度)* IDF(各単語のレア度)
つまり、「その単語がよく出現するほど」、「その単語がレアなほど」 大きい値を示すものとなります。この計算を 「各文書の各単語ごと」 に行うことで、文書の特徴を判別し易くします。TF-IDF計算で求めた特徴(量)は 「特徴ベクトル」 とも呼ばれています。
コサイン類似度
次に、各文書の特徴ベクトルを求め、特徴ベクトル同士の距離(コサイン距離)を計算することで、文書間の類似度(コサイン類似度)を求めます。
コサイン類似度の計算式は下記の通りです。
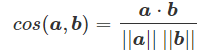
※ cosθ=(文書aベクトルと文書bベクトルの内積)÷(文書aベクトルの絶対値×文書bベクトルの絶対値)
この他にもコーパスと呼ばれる辞書を用意して検索精度を高める工夫や、インデックスの持ち方をアレンジして検索速度を高める工夫を凝らしています。
株式会社 エムエムツインズ